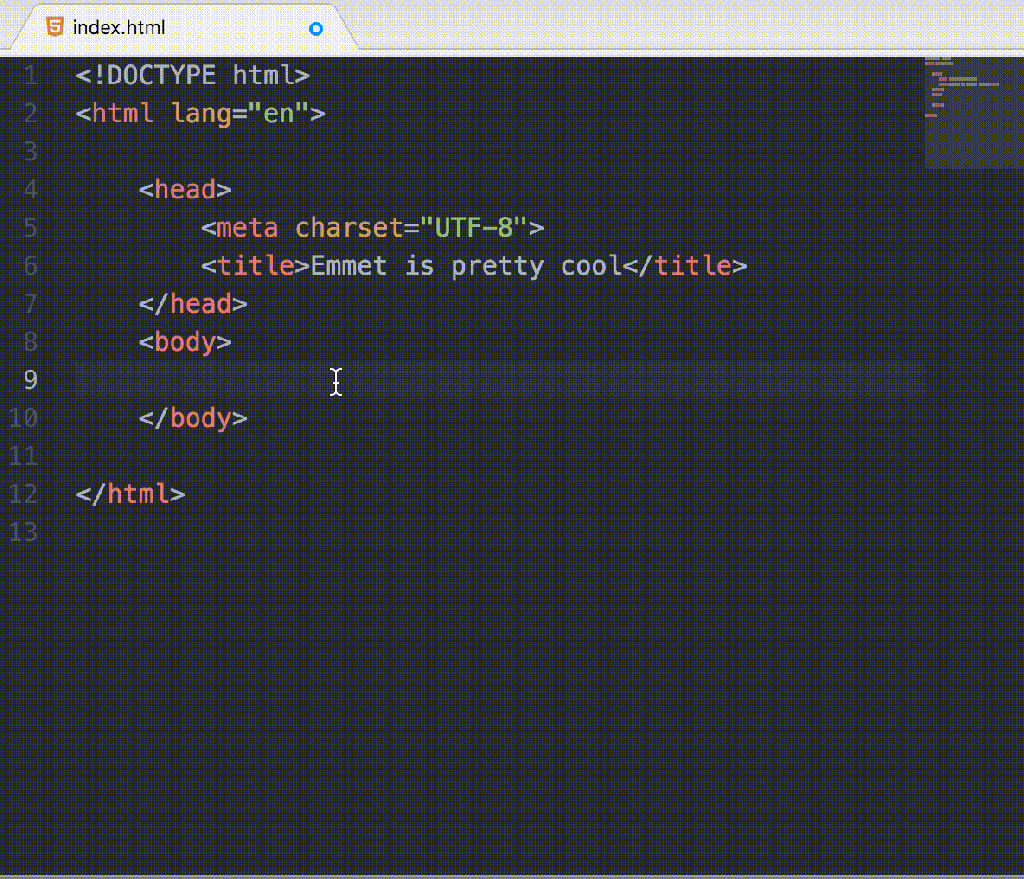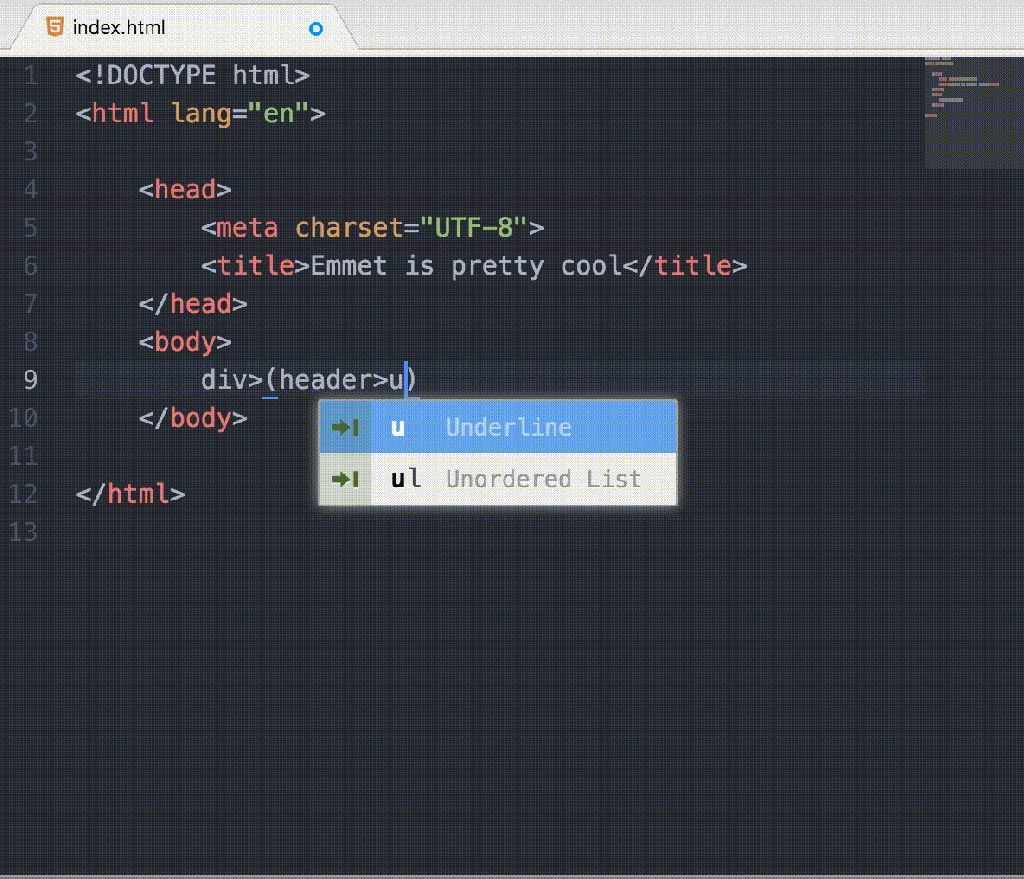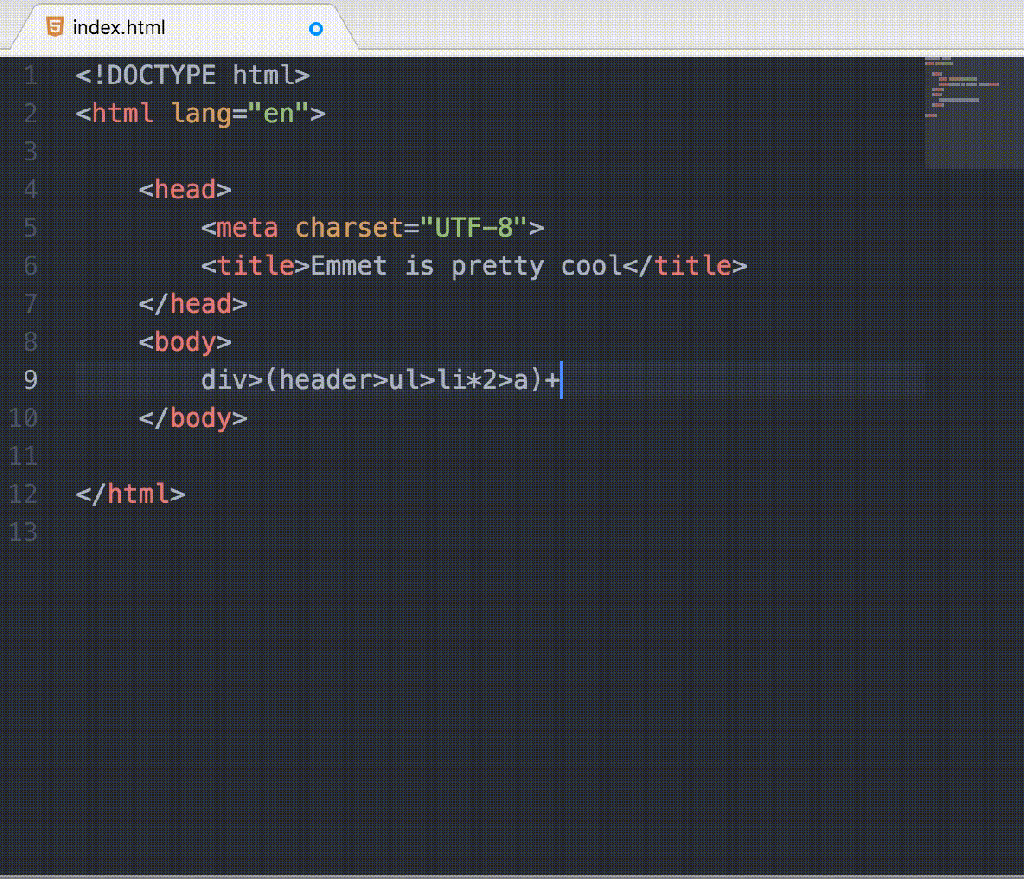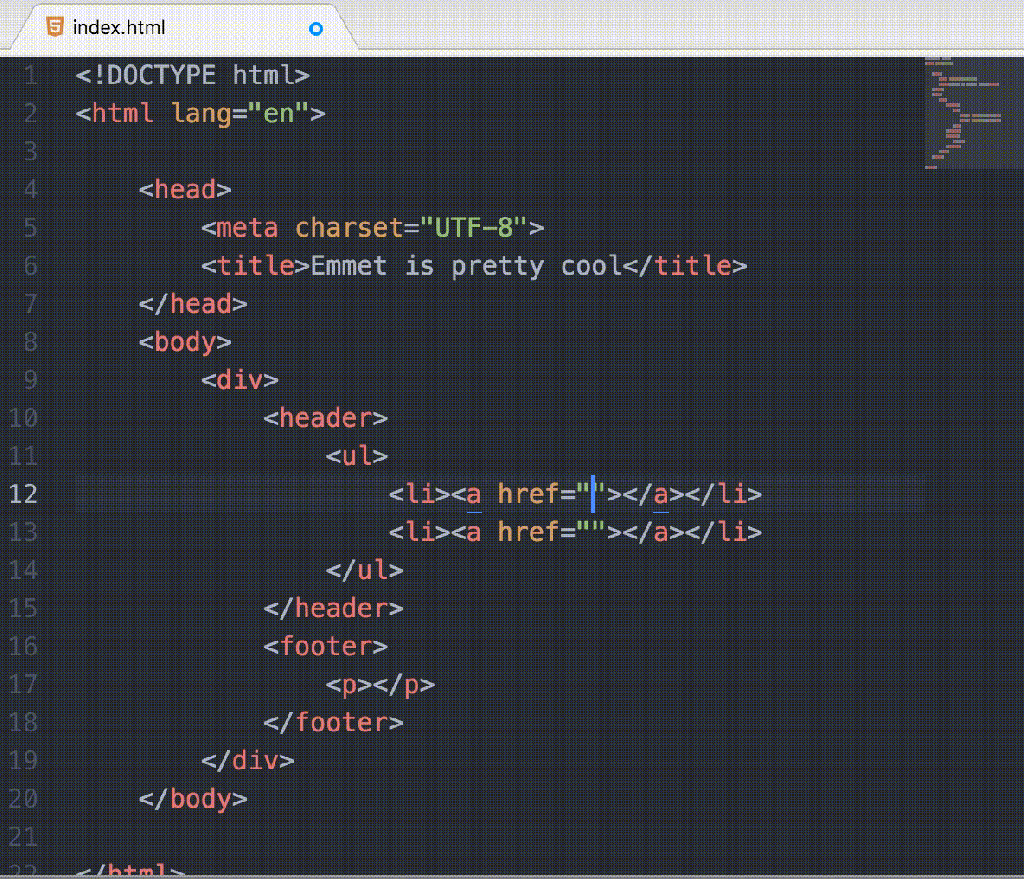
Weeknotes - 22nd May 2017
Strange week this week - coming back from holiday, lots of time spent catching up, arranging meetings and organising more meetings for next week
Monday 22.05.17
Most of Monday morning was spent dealing with all the emails I’d received while away last week. The usual mix of requests for information from admin, queries from current, potential and past students, and a number of things relating to projects that are either about to start or were supposed to have started by now! It took an absolute age to crack through it all. The apocryphal tale of the colleague who just ‘deleted everything’ on the return from holiday with the assumption that anything important would be chased up loomed large in my mind as I replied to my fiftieth message. In a world where ‘responsiveness to communication’ is one of the questions in any number of student feedback surveys, I just don’t think that path is the right one to take.
Monday afternoon saw myself and Glyn working on our talk for Wednesday, taking the usual divide and conquer approach to put together something interesting (we hoped) for the ‘Investigating (with) Big Data’ symposium being held by the Digital Cultures Network.
Tuesday 23.05.17
Another morning of marking this morning. I mentioned last week how pleased I was with the quality of the submissions this year, and it has held up through this latest batch too. The students really seem to have engaged with the module, have thought about what the data says and the message they want to communicate, and have then brought the technical skills to the table to implement their solution. I’m really pleased with how it’s gone. Over halfway through the marking now. It’s supposed to be done by the end of this week, but with two days of training courses and a very busy Wednesday, that’s just not going to happen. I have supplied the necessary apologies to the admin staff and I’m fairly sure they’re not going to hurt me too much.
The afternoon was taken up with meetings with m’colleague, potential CUROP students, and a couple of our MSc CompDJ students who are beginning to think about their dissertation projects for this summer. One of the things Glyn and I discussed was our lack of self-promotion around the activities we do as the ‘Computational and Data Journalism’ team. In the last couple of months we’ve scored research project funding, student project funding, international workshop funding and our students have landed a number of prestigious summer internships, and we’re really not doing a good enough job at shouting about this activity. I’ve resolved to drive this forward a bit better, so came up with a list of potential items for promotion, and I’ll be trying to push those out over the summer, and then keep things ticking over during term time next year.
There was also some movement on the Untappd data project front, as I was finally pushed into responding to my co-investigators with some plans on how to progress from last year’s ICWSM conference paper to a fuller journal paper submission. This is one of those side projects that it’s a real shame to not have more time for, as I think we have a lot of interesting things that we can do, but are all lacking the time to really get stuck in to the analysis. Hopefully we’ll be able to push things forward over summer and get something delivered.
Wednesday 24.05.17
Wednesday started with my first catch up meeting with the DoT for a couple of weeks. I’ve been deputy DoT since September(ish), and we’ve probably not had enough of these meetings. The plan is to make them more regular in the future, and that will probably help with keeping all the plates spinning, as I’m now working on a lot of different projects for the School. We discussed the programme approval process, as we have a number of new programmes in the pipeline as well as some changes to existing programmes going on, and we need to make sure we keep everything coherent. I’ve been tasked with setting up some meetings with the key proposers and the usual suspects within the school to make sure there’s enough coordination going on.
In the afternoon, it was over to John Percival Building to give a talk as part of the ‘Investigating (with) Big Data’ symposium. This was a double hander with m’colleague, and we’d chosen to discuss some issues around large data investigations within news media. Glyn started by presenting some of the more recent large-scale collaborative data investigations that have been carried out by news orgs. I followed that up with a discussion around data openness, transparency, and some of the technical issues that are holding back data journalism. I think the talk went well, people seemed interested and receptive to the ideas we presented.
Sadly I couldn’t hang around for the rest of the symposium as I’d double booked myself for the afternoon, having agreed to go to a briefing for exam board chairs being held over in main building. There’s a few new people taking on the exam board chair role within the school, and although I’m not one of them it was ‘decided’ (no idea who by) that I should also attend the briefing, as I’m probably going to be one of the people called upon to step in if the usual chair isn’t available. It was a fairly dull but not entirely useless presentation on the process of getting ready for and dealing with the aftermath of an exam board. It ticks the boxes though, so now I’m trained and can step into that particular set of shoes if necessary.
Thursday 25.05.17 & Friday 26.05.17
Days 2 and 3 of the ‘Leading Teaching Teams’ training programme that I’d managed to score a place on. This part of the programme was run by the Leadership Foundation for Higher Education, and was probably one of the best training courses I’ve been on so far. I spent a long time reflecting on the way I work, and it really delivered some useful insights. We did a lot of self-assessment and analysis of how our individual approaches may or may not be helpful in managing teams, and I’m looking forward to putting some of the ideas into practice.
As with many of these training courses, one of the added benefits was being able to spend time with colleagues from across the University. It’s always fascinating to find out how others work and to hear about common problems or issues across different schools and colleges, and how they’ve been solved (or not!) in different ways. It’s also nice to get an opportunity to discuss things and to hear that others feel the same way. There was a lot of discussion and dissatisfaction expressed over the 2 days about the increased corporatisation and commodification of Higher Education. I’d love to tell you that we’ve solved that particular issue, but sadly not. Many did get righteously angry about it though. I suspect a higher societal change is needed to fix it, and all we can do at this level is to keep pushing for that change.