So, lets say that hypothetically you have written a set of course notes in an 11ty site and you want to add some quizzing to the pages so that students can quickly check their grasp of the material they’ve just read. How would you do that? Here’s a possible solution…
Data files
The first issue - where can we store our questions that we’d like to quiz readers with? Eleventy templates can pull in data from all sorts of places. One such place is any *.11tydata.json file that has the same name as one of your markdown files. So, if we have a file variables.md , we can store some questions as json in variables.11tydata.json, and this data will be made available inside the final variables page. An example data structure might look like this:
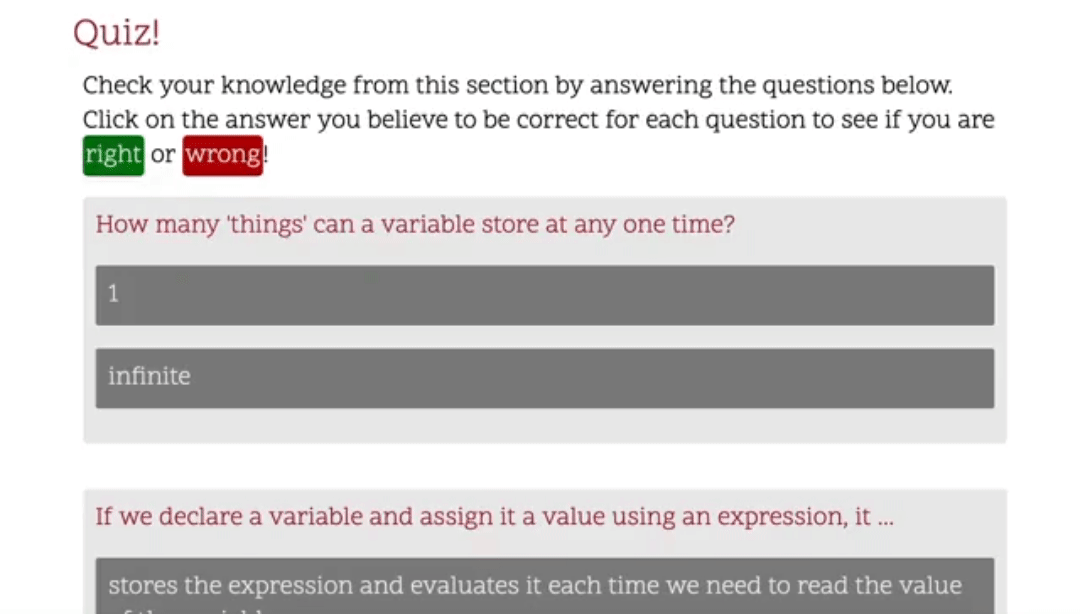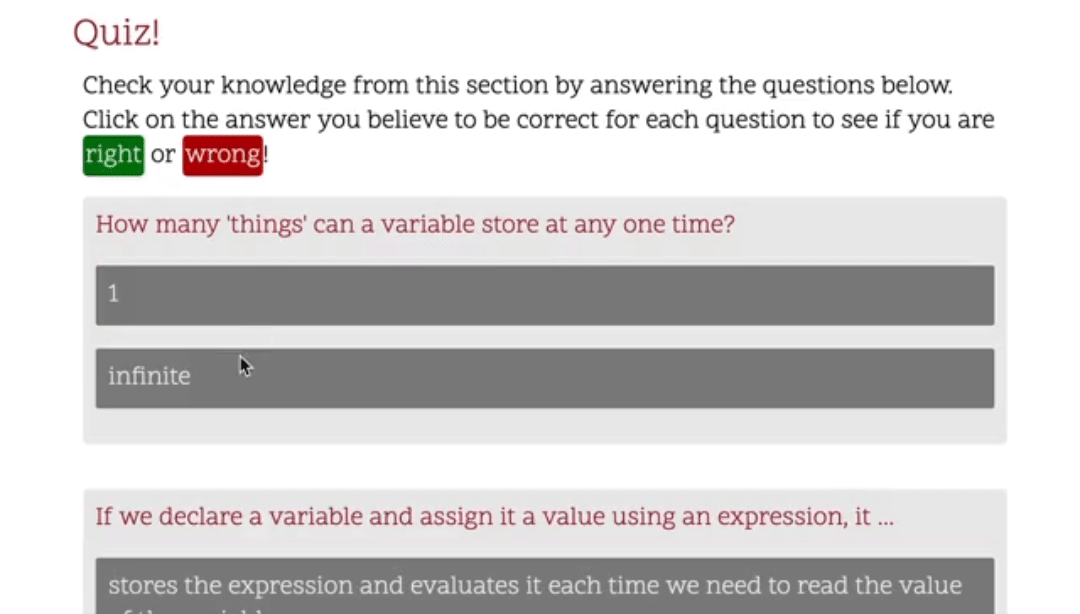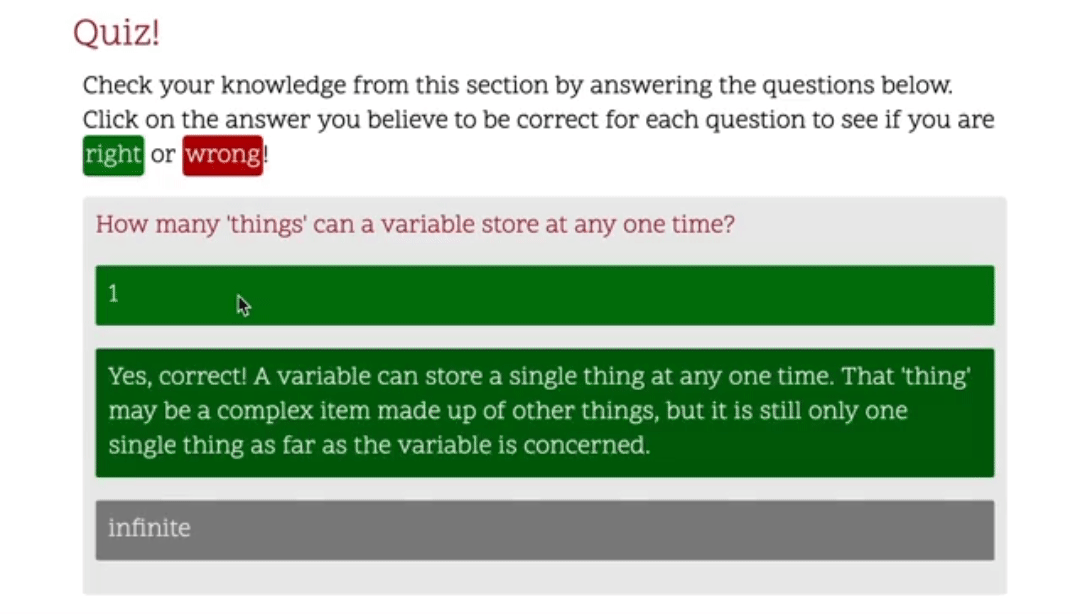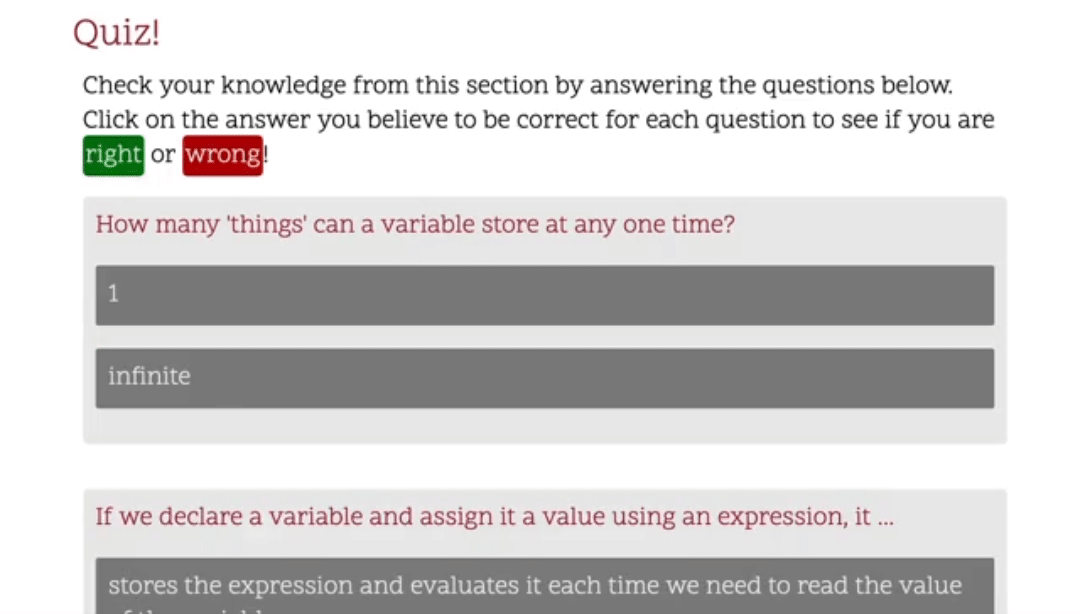
{ "questions":[ { "question":"How many 'things' can a variable store at any one time?", "answers":[ { "answer":1, "correct":"true", "feedback":"Yes, correct! A variable can store a single thing at any one time. That 'thing' may be a complex item made up of other things, but it is still only one single thing as far as the variable is concerned." }, { "answer":"infinite", "correct":"false", "feedback":"No, sorry, that's incorrect. Each data item we store in a variable takes up an amount of the computers available memory. To store an infinite number of values in a variable we would need a computer with infinite memory. This does not currently exist." } ] }, ...
The questions object inside the .json file will end up as a variable inside our page template. So, given that, how do we get the questions from the .json and into the page?
Shortcodes
11ty allows us to define our own shortcodes that mean we can create reusable snippets of code (layout etc) that we can use all over our 11ty site. We could define an 11ty shortcode as a JavaScript function that takes our questions as input, and returns the HTML code that should be inserted into the template to display the question:
And now our shortcode is available to be used in our variables.md file:
{% questions questions %}
Once 11ty has done it’s magic and built our site, we end up with:
<divclass="question-block"id="q-block0"> <pclass="question"id="q0">How many 'things' can a variable store at any one time?</p> <divclass="answer-block"id="a-block0"data-correct="true"> <pclass="answer"id="a0">1</p> <pclass="feedback hidden"> Yes, correct! A variable can store a single thing at any one time. That 'thing' may be a complex item made up of other things, but it is still only one single thing as far as the variable is concerned. </p> </div> <divclass="answer-block"id="a-block2"data-correct="false"> <pclass="answer"id="a2">infinite</p> <pclass="feedback hidden"> No, sorry, that's incorrect. Each data item we store in a variable takes up an amount of the computers available memory. To store an infinite number of values in a variable we would need a computer with infinite memory. This does not currently exist. </p> </div> </div>
So that’s the data in a nice format for storage and editing, nicely separated from the notes content, but able to be inserted into the final built page. How then do we make it into a real quiz, where the reader can choose an answer?
Bring on the JavaScript!
Yes, we’ll solve this problem the way we solve everything in web development … we’ll throw a load of JavaScript at it:
Okay, it’s not really a large amount of javascript.
We add this into our page layout, and then it’ll be present on all the notes pages. This JS will find all the answers in our page and add a listener to them that will fire whenever someone clicks on one of the answers. The listener calls a function which finds the feedback associated with that answer and toggles a ‘hidden’ class, which we’ll use to show and hide the feedback. It will also toggle the ‘selected’ class on the answer itself. That’s all the JS we need for the answer selection, so what gives us the rest of the quiz functionality?
Bring on the CSS!
Yes! We could do a whole lot of this in JS, but JS is very bad and we should keep it to a minimum. So let’s do the showing and hiding with CSS instead. Actually .sass in this case:
Here we set the .hidden class to display none. This way any feedback with the hidden class applied will be hidden, and when the hidden class is removed (when we click on an answer) it will be shown. Then in the second set of rules we select the answers that are incorrect and colour them a shade of red, and colour the answers that are correct green. Job done.
I’m re-writing some course notes, as I usually do at this time of year, and I’m trying to separate things up into small reusable chunks, so that rather than building a comprehensive set of notes/videos/resources for an entire module, I create a range of small short-course type resources on different topics that can be built up for my module, or made available to be re-used by other people.
Previously, I’ve created websites for a module using a static site generator. This year, having fallen out of love with Hugo I thought I’d see about using 11ty.js for this task.
There’s some drawbacks in abandoning Hugo for 11ty as far as the ‘quickly get a set of course notes up and running’ goes. Chief among these is that as a ‘young-ish’ technology, 11ty is still maturing in the ‘themes’ department and functionality. Whereas there’s a rich set of templates and themes for creating academic/instructional courses using tools like Hugo or Jekyll, there’s not that much out there for 11ty, so rather than adapt an existing example (which tend to be more for portfolio sites or blogs) I figured I’d build this from scratch.
The approach I’ve taken looks a little something like this. This is still a WorkInProgress, so I expect some of this will change as the semester goes on, but as a starting point I’m pretty happy with where I am.
Contents
The contents of the notes are written in markdown. Nothing complicated here, just regular markdown. I don’t tend to do anything too fancy as far as mathematics or diagrams are concerned, so a fairly basic set of markdown notes, arranged into sections based on topic in a notes folder, with a top-level index and an about page:
See those json files? We’ll come back to the variables.11tydata.json in the future but the notes.json is a shortcut file, all it has in it is:
{ "tags":"notes" }
This means that anything in the ‘notes’ folder will be tagged with notes. 11ty automatically builds collections based on tags, so by tagging everything in the folder with ‘notes’ we automatically get a collection of those pages we can use later.
For a set of course notes or documentation there’s two things I like to have:
a navigation menu that leads to each of the pages and allows us to view the overall structure
a way to step through the pages in order one after the other
Sidebar navigation
I’m using nunjucks templates for the page layouts here. Part of the notes page template looks like this:
--- layout: base.njk ---
...
<navclass="sidebar"> <ahref='/'>Home</a> <ul> {%- for note in collections.notes | sortByPageOrder -%} <li><ahref="."></a></li> {%- endfor -%} </ul> <ahref="/about/">About</a> </nav>
...
Here we loop through our collection of notes to add a link for each page to the navigation. 11ty automatically orders collections by date. This doesn’t suit our purposes as we want to order the pages by topic so that readers can follow the notes in the correct order. So, we add an order data item to the .yaml data for each page:
--- layout: page order:6 title: Iteration ---
We write a function in our 11ty config that will sort pages by this order variable, and add it as a filter, referenced in the template above:
Now we can determine the page order and the pages will be listed in our navigation in the order we specify.
Stepping through pages
11ty has a nice pagination feature for collectons that means once we have a collection that’s ordered, we can easily find out what page is next in the collection. We can use this in our notes page template to add stepping links backwards and forwards through our pages just below the page contents:
<divclass="nextprev"> {%- set nextPost = collections.notes | sortByPageOrder | getNextCollectionItem(page) %} {%- if nextPost %} <pclass="next">Next: <ahref="."></a></p> {% endif %} {%- set previousPost = collections.notes | sortByPageOrder | getPreviousCollectionItem(page) %} {%- if previousPost %} <pclass="previous">Previous: <ahref="."></a></p> {% endif %} </div>
Putting this all together with a (pretty much) default 11ty setup and a little CSS to lay things out nicely we end up with a nice documentation/course notes site that has navigation between each topic, all built from markdown.
Since this whole lockdown thing happened, I’ve hit the running hard. Since the start of March I’ve run about 600km, which is about 200km more than I ran in the whole of 2019. I’m using running as stress relief, and there’s a lot of stress around, so there’s a lot of running to be done.
While I’m running so much, and partly as a motivator to ensure I don’t slack off and stop running I thought I should enter some virtual events. I found the events I needed in the Wales Coast Path (WCP) and Lands End to John 'O Groats (LEJOG) virtual runs being put on by EndToEnd running. In these events you have a year to ‘virtually’ run the length of the Wales Coast Path (870 miles) or from Lands End to John 'O Groats (874 miles).
Being the data nerd I am, I wanted to be able to track my mileage in quite some detail, and hopefully predict when I should be able to finish these ridiculous challenges so of course I had to analyse it with a bit of Python. I’m storing data in a simple spreadsheet like this:
Day
Date
Mileage
Cumulative
1
13/07/2020
12.99
12.99
2
14/07/2020
0
12.99
3
15/07/2020
0
12.99
4
16/07/2020
6.45
19.44
Loading this in to Pandas is straightforward, even more so using the excellent pathlib library, which I cannot recommend enough for manipulating files and directories
# how many miles should we run each day for the given target? RATES ={} for run in RUNS: RATES[run]={} for target in TARGETS: RATES[run][target]= LENGTHS[run]/target
This spreadsheet has the dates for the rest of the year already entered, but we only want to analyse the data up to the present day and not worry about the future (an excellent life strategy, if not entirely sensible), so lets get rid of days with no data:
for run in RUNS: run_data[run]= run_data[run].dropna()
So the first thing we want to do now we’ve cleaned the data is work out what our current run rate is in miles per day, and how much distance we have left for both of the runs:
CURRENT_RATES ={} REMAINING ={}
for run in RUNS: last_run = run_data[run].iloc[-1] CURRENT_RATES[run]= last_run['Cumulative']/last_run['Day'] REMAINING[run]= LENGTHS[run]- last_run['Cumulative']
Once we know how many days we have left, we can add that to the first run date, and work out when we should finish each race:
PROJECTED_END ={} for run in RUNS: first_run = run_data[run].iloc[0] start_date = first_run['Date'] PROJECTED_END[run]=(start_date + timedelta(days=DAYS_TO_FINISH[run])).date() print('Predicted to finish {0} on {1}'.format(run, PROJECTED_END[run].strftime('%A %d %B %Y')))
which lets us know that:
Predicted to finish WCP on Sunday 24 January 2021
Predicted to finish LEJOG on Wednesday 17 March 2021
So just another 5 to 8 months of running to go. Best go get my trainers on again …
if you want to see the full code I’ve used, it’s in github
I know, it looks exactly the same. But underneath it’s all new, I promise.
This is actually version 3 of my website. The first version ran on Jekyll, which was fine, but then it got to the point where I had a couple of years of blog posts and it was taking a really long time to rebuild the site, which slowed me down a bit too much. There was also this feeling nagging at me that I didn’t really understand what was going on underneath. I don’t know Ruby, the language Jekyll is written in, so whenever I wanted to do something out of the ordinary I’d have to hack it together in a language I didn’t really get from whatever information I could find online.
So a couple of years ago I swapped the build for the website to Hugo. I pulled all the content out of the old Jekyll site, smushed it into a Hugo site, smushed my ‘design’ (such as it is) into a Hugo theme, and replaced enough of the Jekyll plugins with existing Hugo plugins or self-written shortcode templates that it basically all worked. Hugo is written in Go, and is much faster at building than Jekyll, so the build speed issue was solved! However I still had the feeling nagging at me that I had no real idea what was going on underneath. Again, I managed to do the things I wanted to do, but it was hacking things together again, and it mostly only worked out of luck. I then had a slightly worse problem, which was that because I only update the website so infrequently, whenever I do come to post an update I’m usually working on a different system on which I’ve never built the website before. Which is fine for most of the build process, but I’d never bothered pinning the version of Hugo, so everytime I rebuilt I’d skip ahead a couple of releases, and find that something had changed and one of my shortcodes was now broken, and it’d take me a couple of days to find the time to sort it out, and by that point I wouldn’t be bothered actually writing the post I’d originally intended to write…
I know. A good workman never blames his tools… but that’s generally how it would go.
And so then we come to now. Or rather, a couple of weeks ago, when I decided I wanted to write a couple of blog posts, and found myself setting up a build environment on yet another laptop, and running into a problem because Hugo didn’t like something and wasn’t building the site right, and I finally ran out of patience and started looking around for an alternative.
The alternative I found is Eleventy. Eleventy is a Static Site Generator just like Jekyll or Hugo, but it’s written in JavaScript. “Aha!” I thought. “A language that I actually know some of. If I use that to build my site I probably still won’t know what’s going on under the hood, but at least I’ll know it’s doing it in a language I’m familiar with!”
So I took the content out of the old Hugo build, smushed it into an Eleventy site, patched together some JavaScript to build the more complicated bits, and voila! A super-fast build process, in JavaScript. Wrapping that in the existing process for building sass, minimising CSS and HTML, sprinkling it all with a little responsive image magic and pushing the result over to Netlify and the site is ready for action once more.
Today I’m on a visit (with several other members of staff from the School of Computer Science and Informatics) to TU Eindhoven, being hosted by the Department of Industrial Engineering and Innovation Sciences. We’re here to talk about both teaching and research mostly on a fact-finding basis, but also with an eye towards potential future collaborations and links between the two institutions.
It’s always fascinating to visit other academic institutions, particularly in other countries. In the first instance, seeing the differences in the way they do things can be very eye-opening and lead to some interesting ideas that can hopefully bring about substantive and useful changes back home. Secondly, it is also kind of reassuring to see that there are similarities in the problems they face, and that some of the questions they are wrestling with internally are very similar to the questions we spend time discussing.
On the teaching side of things, we’ve been learning about their extensive use of problem-based learning, their cross-curricular project space, and their vision for what education at TUE will look like in 10 years time. We’ve learnt a lot, and it’s really spurred us on to think about the long-term plans for education in the School - where do we want to be in 10 years, and what will CS education look like then?
Our next step is to try and figure out the answer to that question…
So I finally started writing again up there, but it all seems so incongruous with the post down below, which still makes me cry whenever I read it, so I think there’s some sort of buffer needed between the super-emotional ‘my mum died’ stuff and the totally fluffy “here’s a bit of useful code” stuff so here’s a break of sorts. I didn’t write this on the 16th March, but that’s very much a date connected with the start of coronavirus lockdown madness for me, so I cheated this post into this date. Bite me.
Last Sunday I left the house at a little after 8am to cycle from my home in Penarth over to Cardiff. It was the day of the Cardiff Half Marathon, which I was participating in for the second time, raising money for cancer research at Cardiff University, for reasons that will soon become obvious.
The air was clear, the sky was blue, the sun was bright. There was still a slight chill in the air, though you could tell it would be warming up quickly. I cycled out of Penarth and over the Barrage which on a good day is a lovely ride, and it was a really good day. You’re surrounded by water on both sides: to the left you have the lake of Cardiff Bay and to the right the Severn estuary. If you’re lucky the Severn isn’t as brown as usual, but even when it is, it’s nice to be looking out over the water to the English coastline a few miles away, especially with the sun reflecting back at you. It felt beautiful, and the day had an air of positivity. As I left the barrage and headed up Lloyd George Avenue towards the city centre I passed groups of runners all heading towards the Half Marathon start line, all of us carrying that mix of excitement and nervousness before a big event.
Meanwhile, 120ish miles away in a hospice on the outskirts of Shrewsbury my mum died.
Mum raised me and my sister pretty much single-handed for an awful lot of our childhood. My parents divorced when I was around 5 years old, and though my Dad wasn’t exactly ‘absent father’ he wasn’t really that present either, beyond the few hours on a Sunday when he’d take us off bowling or to some other part-time divorced dad & kids type activity. So mum did most of it, supported by her parents I suppose, and the occasional boyfriend. She worked full-time at the local sixth-form college, and I never really knew what her job title was, but it had something to do with ‘reprographics’, a job that I suspect does not exist any more. This was back in the late 80’s early 90’s, so we’re talking full-on recession and ridiculous interest rates, when even a full-time job wasn’t really enough to keep us afloat. She often worked more than a full-time job; heading out in the evenings to teach IT evening classes, or working weekends manning the sales office at one of the housing developments being thrown up around the Shropshire countryside by the company her boyfriend at the time worked for.
I have no idea how she did it.
We both work full-time and we have two kids and we are both knackered. I cannot fathom how on earth she did it on her own for so long.
As we got older she went to University part-time, getting herself an MBA, studying mostly at night at a University of Wolverhampton campus just down the road in her home-town of Telford. At the time I knew she was working hard to get the degree, but it was only when I finally got to University myself that I really understood the effort it had taken for her to manage it. Again, a feat accomplished while working full-time and looking after two children. And I know loads of people do it, but that doesn’t make it any easier. A few years ago as I was coming to the end of my PhD my wife embarked upon a part-time law masters while also working full-time, and it nearly ended us both, and we didn’t even have anything to look after at that point other than a goldfish. For mum to accomplish what she did was impressive. To accomplish what she did without moaning or complaining was beyond impressive.
She wasn’t always brilliant, and she wasn’t perfect of course. One of her weaknesses was an inability to deal with people throwing up; bad news when raising two teenagers in a provincial market town in the days before Challenge 25. She just could not cope with the vomit. And of course, as a teenager I fell out with her in numerous ways, for stupid reasons and good reasons. That’s what teenagers do, I assume. She was always mum though, and it was always alright in the end. And I grew up and stopped being a hormonal dick and it turned out she was still there waiting for me at the end of an evening out. As long as I wasn’t being sick.
I have a lot of memories of spending time with her travelling to various university campuses trying to decide where to go. She liked Birmingham. I liked Cardiff. I ignored her advice. By the time I was going off to University she had moved on with her career and was now working as an IT trainer/consultant. Her work meant that she travelled a lot, and fortunately it brought her to South Wales with some frequency, so we were able to meet for lunch quite often, or she would come and stay with us overnight rather than sleeping in a travelodge. She moved between companies a few times as she got older and I would always be a little sad when she went to work for someone with no customers in the area.
She re-married eventually, to Ed. Ed’s a man whose politics are completely wrong and at the other end of the spectrum to mine, but whose heart is fundamentally in the right place. Ed loved mum, and she loved him. They had many happy years together, living what seemed to be a comfortable double income no kids life that mostly revolved around pubs and wine. When our children came along they ended up with three granddads, because that’s how families are. And my mum knitted them little hats, and cardigans, and teddy bears. And when I asked her to knit Arthur a hat that made him look like a fox, she made me one too so that we could match.
My mum was brilliant, and I love her.
My mum was diagnosed with kidney cancer in April this year. By the time they caught it there was a tumor on one kidney, and the artery connected to the kidney, and it also looked like it had spread to her lungs, so we were already in ‘oh shit’ type territory. But, there was hope that with an operation and some treatment, we could have a few more years left with her. Over the course of the next six months she had a kidney removed, waited to recover a bit before starting treatment, had a course of immunotherapy that messed her about quite a bit, and we were then very quickly into the realm of “well, I’m afraid this isn’t going to work, so there’s not a lot we can do beyond making sure this doesn’t hurt too much”. She went in to the hospice ‘to try and get her breathing stabilised’ a week before she died, where things quickly progressed from “I’ll be out in a bit” to “I’ll not be out, but I’ll be around for a few weeks” to “She’s got days” to finally 7 days after she went in: “She’s got hours”.
I saw her a lot this last year, though not as much as I would have liked. At lot of her problems in the last few months were connected to her chest, and either I or the kids were always full of a cold or some other chesty-type lurgy, so while there was still hope we didn’t want to be bringing her any new bugs to contend with. That caused a few trips home to be cancelled. But I saw her fairly regularly, and spoke to her more often than I had. Recently I was on a training course and during a particularly reflective session the facilitator was discussing the death of his own mother and reflecting on the things that were left unsaid. It stuck with me, and I made sure to tell mum everything I thought she needed to know before the end. I am grateful for that. I got to say all the things that needed to be said.
My final visit to see her was last weekend. I drove up on Friday evening, and got to Shrewsbury at about half-nine. By this point she was pretty well out of it, and we were basically expecting her to go at any moment. I spent some time with her on Friday, both with my sister and alone, and then spent several hours by her side on Saturday with my sister and stepdad, as a number of friends popped by to say their goodbyes. Nobody was really sure how long she had left, so I was reluctant to leave, but I felt I had to run the half.
I’ve got a history of running in the not too-distant past, but I’d not really run seriously since I last ran the half in 2016. A mixture of laziness and tiredness from children had led to me losing a lot of my running fitness over the last three years. In April I was visiting Shrewsbury at the same time as a good friend, who convinced me to go to parkrun for the first time. I did, and really enjoyed it - it sort of rekindled my love for running, in a way that the few 3/4km solo runs I’d managed in the last year really hadn’t. By a strange coincidence, that was the same visit to Shrewsbury where my mum told me about her diagnosis. It’s not that I overreacted (I did), but within a short time frame I had decided that now I was officially a runner again I should enter the Cardiff half to raise money for cancer research. So I did. Six months of training followed, and unlike the last time I was running seriously, this time I had a more powerful motivation. Running was an outlet; somewhere to put my anger and grief. The emotion I might in an earlier time have buried under a couple of strong beers I instead pounded into the pavement, each step bringing me closer to the acceptance we all must find when these things happen. Several hundred kilometres of pseudo-running-therapy had led to that one race, and several very generous people had donated enough to put me well beyond my fundraising target, so it was never on the cards that I’d skip the run.
Saturday afternoon came, and my mum was still going. She wasn’t going to make it easy on me and go before I had to. I said goodbye to her, knowing as I did it that unless some sort of miracle occurred it would be our last goodbye. Needless to say, it was an emotional afternoon. I drove back to Cardiff, expecting at any moment to get the call to say she’d gone.
No call came.
So I ran the half. I ran it faster than I’d planned, and faster than I really should have. On the way round whenever I was too tired, I thought of mum, and it kept me going, pushed me onwards. At the start I’d hoped to keep up with the 2 hour pacers - it would be faster than I’d ever run the distance - but by 2 kilometres in I’d left them behind. I knew it was silly pacing, but I wanted to go for it. I paid for it as I knew I would; by the time I got to 11k it was hard going, and by 14k I was concerned about making the distance. But any thoughts I had of quitting were quickly replaced by thoughts of my mum, and how much I wanted to finish the run for her. Given the role running had played in my dealing with grief and sadness over the last six months, part of me had been moderately concerned about what would happen when mum was gone. Would I still want to run? Emotions have powered me to quite a few PBs in the last few months, but this run was different. I wasn’t feeling angry anymore, I wasn’t overloaded with the grief and the sadness. I was happy. Foot in front of foot, and despite the tiredness and the aches and pains, I was happy. I knew that mum’s journey would soon be over, but that it was okay. So I ran the half.
I crossed the finish line. I’d smashed my time. I wandered through the post-race crowd in a bit of a daze, and had a not-insignificant cry as I did so. You see people crying after races sometimes. I assume some of them are just crying with joy at having done it, but I realise a fair few are probably just like me, overcome with emotion because of their reasons for running the race.
I got home and Lisa greeted me on the stairs and I knew then that mum was gone. Arthur confirmed it in fairly short order, with the bluntness that only a four year old child has when delivering bad news. His mum had literally just ten seconds ago told him to let her discuss things with me, but like all good sons he ignored the advice of his mother and did it anyway. It didn’t really matter, because I already knew. I’d known since Tuesday of that week that she was going to die on the day of the half marathon. I’m not a spiritual person, and I don’t have any religion, and I don’t believe in a higher power; but on my run in to work on Tuesday I’d suddenly realised that of course that was the day she was going to go. I didn’t know why, but I knew it was what would happen. So I knew I had to run.
It turns out she’d passed away earlier in the morning, before the race began, at around about the same time as I was cycling across the barrage and thinking about how much of a beautiful day it was. My stepdad had thought about whether to tell me before the run and decided against it, a decision I completely agree with. I don’t know what would have happened if he had. It doesn’t really matter. She died, and I ran. We raised a chunk of money for research. Along the way I re-kindled my passion for running, and as soon as the little niggle I picked up last weekend has healed I’ll be putting the trainers back on and getting ready for the next one.
Next time I’ll be raising money for Severn Hospice, the fabulous people who looked after mum so well for the last week and a bit of her life.
Just a few days after a very successful datajconf I hit the road again, this time to head to Paris for the World Journalism Education Congress. An entirely different sort of conference, this aims to bring together educators from all over the world to discuss the past, present and future directions of Journalism education. The conference is big, with over 500 attendees, and has been running for over fifteen years (although it actually only takes place once every three years, so is on its fifth edition).
It was interesting to be attending an education conference outside of what I’d consider my usual area. I wasn’t the only Computer Scientist there (in fact there were a number of us), but of course the main focus was on general journalism education, and I’ll be the first to admit that while I have a good amount of knowledge of the area, I’m not an expert. However, the issue of Data Journalism (and to a smaller extent Computational Journalism) education loomed large over many parts of the conference, and on that topic I do have a very good amount of knowledge. We’ve been teaching in this area for over five years now, and it was great at the conference to be able to talk to other educators who’ve been teaching in a similar area to have our experiences and approaches validated. It was also very interesting to be able to contribute to discussions at the conference from a position of expertise, particularly in being able to help other people who were looking to start similar programs, or who are wanting to begin covering data journalism in a wider context in their own schools. I spent some time working within a syndicate looking at Data and Computational Journalism education, starting to move towards an understanding of the skills that are needed to be covered ‘as a minimum’ if you’re going to cover these areas within general journalism education. I was pleased to be able to introduce the idea of computational thinking to a number of educators, and to discuss the ways in which it can be useful as a thought process outside of computer science, and how well it maps to some of the processes involved in journalistic investigation and data driven journalism.
Data literacy, computational thinking and commmunicating data are the most important topics in data journalism education according to @fstalph, the rapporteur of data journalism syndicate.#WJECParis#data#journalismpic.twitter.com/Nqpi9GmUn3
In fact, many of the conversations at the conference made me realise just how cutting-edge our MSc Computational and Data Journalism is, and how important the skills we teach are. A number of employers spoke to me about how they need people in the newsroom with the abilities that you get from our course, and many more other educators mentioned how they wish they could convince their own school to create a similar programme.
It's been a very interesting few days, and also very pleasing to see that the kind of teaching we've been doing here @CardiffJomec and @CompScienceCU for the last five years is now being taken on by more j-schools and i-schools all over the world
We’d actually had a paper accepted to the conference, presenting a reflective look at the first five years of the CompJ MSc. I’ll post more about the talk I gave (and the slides!) in a future post, but the talk went well and we had some interesting discussions afterwards. Unfortunately, the paper sessions were in my opinion some of the weaker sessions in the conference. There were many many parallel tracks going on at the same time, so that the audiences tended to be very small. At the same time, the conference app (which was very cool) only listed titles for the papers in each session, so it was hard to know what each session was going to be about, and in many cases the theming tended to be quite loose (maybe even a bit random!), so that papers in the same session didn’t always have a lot to do with each other. Still, with the number of submissions, papers and contributors it’s a massive logistical challenge to put such a programme together, so I think a little leniency is allowed!
Overall it was a really great experience. I met some lovely new people, caught up with a few old acquaintances, and I look forward to working more with them in the future.
Last week we held the third edition of the European Data and Computational Journalism Conference in Malaga, Spain. This is the conference that Glyn, Bahareh and I run, which started in Dublin in 2017, had a second edition in Cardiff last year, and has now embarked upon a journey around the European mainland. It was a fantastic event, with around 100 attendees representing different organisations from across industry and academia, and from 14 different countries. As with last year we had a first day presenting a mix of industry and academic talks, and a second day with a focus on more practical workshops and tutorials.
When Bahareh initially pitched the idea of running a conference in this field one of the main drivers for us was to encourage a mix of industry and academia, as we think the conference can be more useful this way. It has been a great pleasure to see this happen over the last three years, with both academics and practitioners putting forward talk proposals, coming along to the conference, and starting what I hope are interesting and fruitful conversations. By not splitting the conference into ‘industry’ and ‘academic’ tracks we’re able to ensure that all involved in data and computational journalism get to see all sides of the field, and this is a really positive outcome for the community. I’m excited to see some collaborations starting to happen that may not have happened if people hadn’t got together at the conference, and I think this is really one of the key benefits of this conference as a venue.
There were some truly interesting talks on both days, and some very interesting practical workshops too. Our keynotes, Daniele Grasso and Meredith Broussard did fantastic jobs of opening and closing our first day of talks. Our local hosts did a spectacular job with the organisation. Bella and the team put together a local program that was welcoming and inclusive, and showed off Malaga to its fullest. We as organisers all agreed that the job the team had done was fantastic, and they’ve set the bar very high indeed for wherever the conference goes next.
The roundup video gives a really good overview of what the conference looked like:
Like many (most?) people these days who have the foolish notion to exercise outside I track my activities with GPS and a logging app. Well, I say ‘app’, but of course with the way all things link together my data ends up shared between four or five different services.
I recently had call to download my location data for an upcoming project. One of the sites that stores my running and cycling activity is Runkeeper, and it was from here I chose to pull my data.
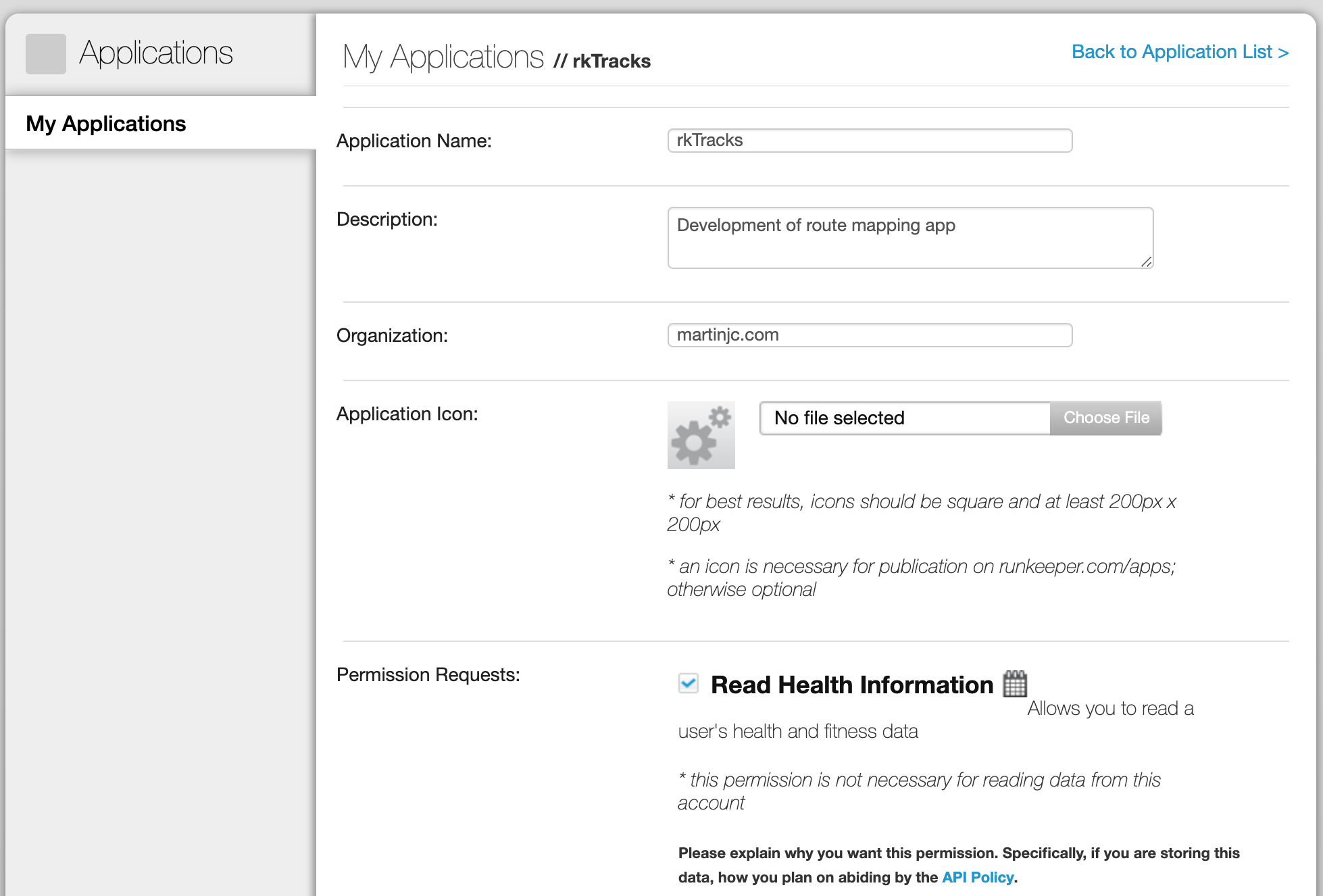
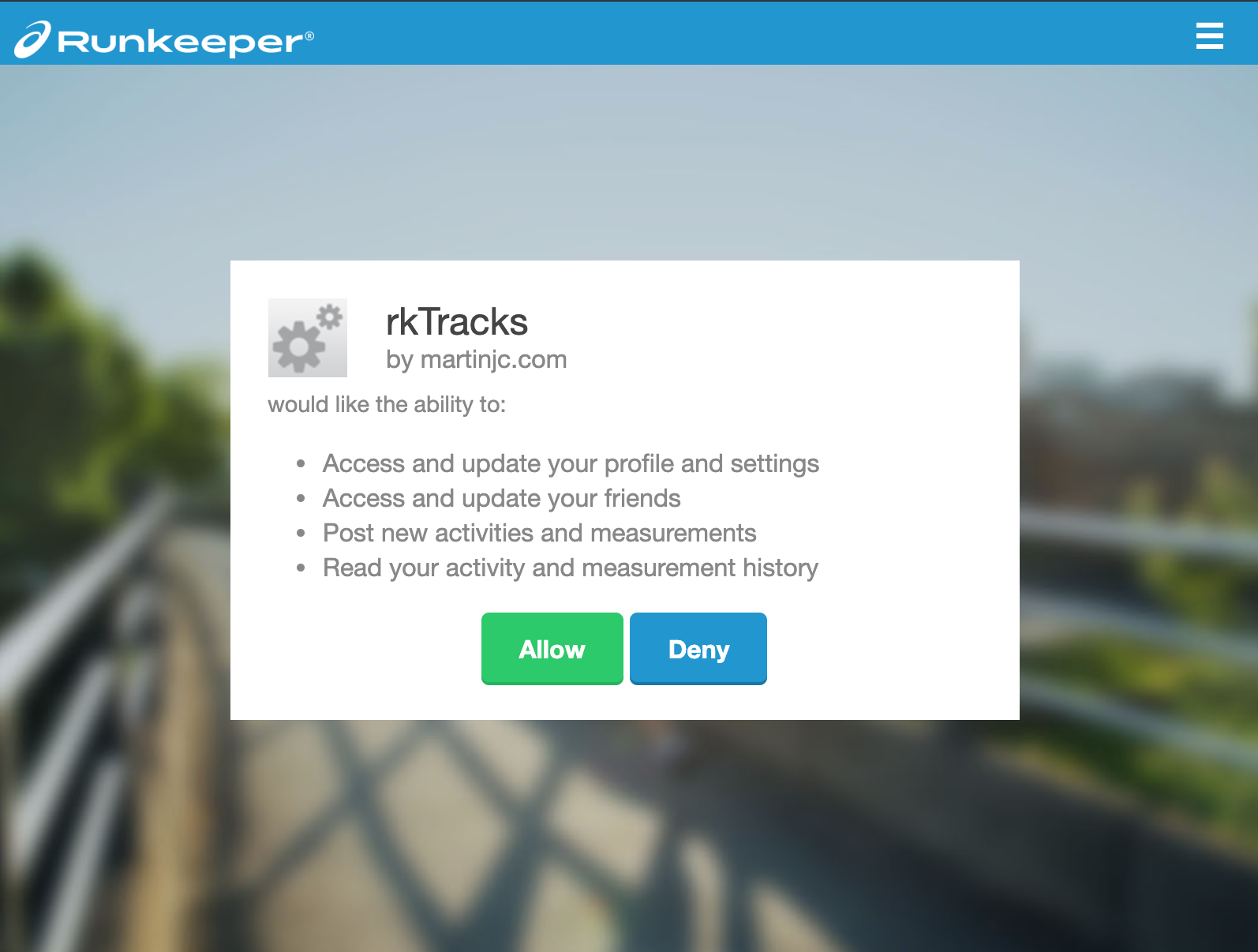
Runkeeper has an API, and if we’re going to pull our data out of the service the first thing we need to do is sign up to use it, which you can do at the Health Graph website. The link to sign up is buried slightly in the documentation - but you can sign up to create an app at https://runkeeper.com/partner/applications. You need to enter a few details for an application - as we’re only going to be using this for accessing our own data it doesn’t really matter what information we put in here:
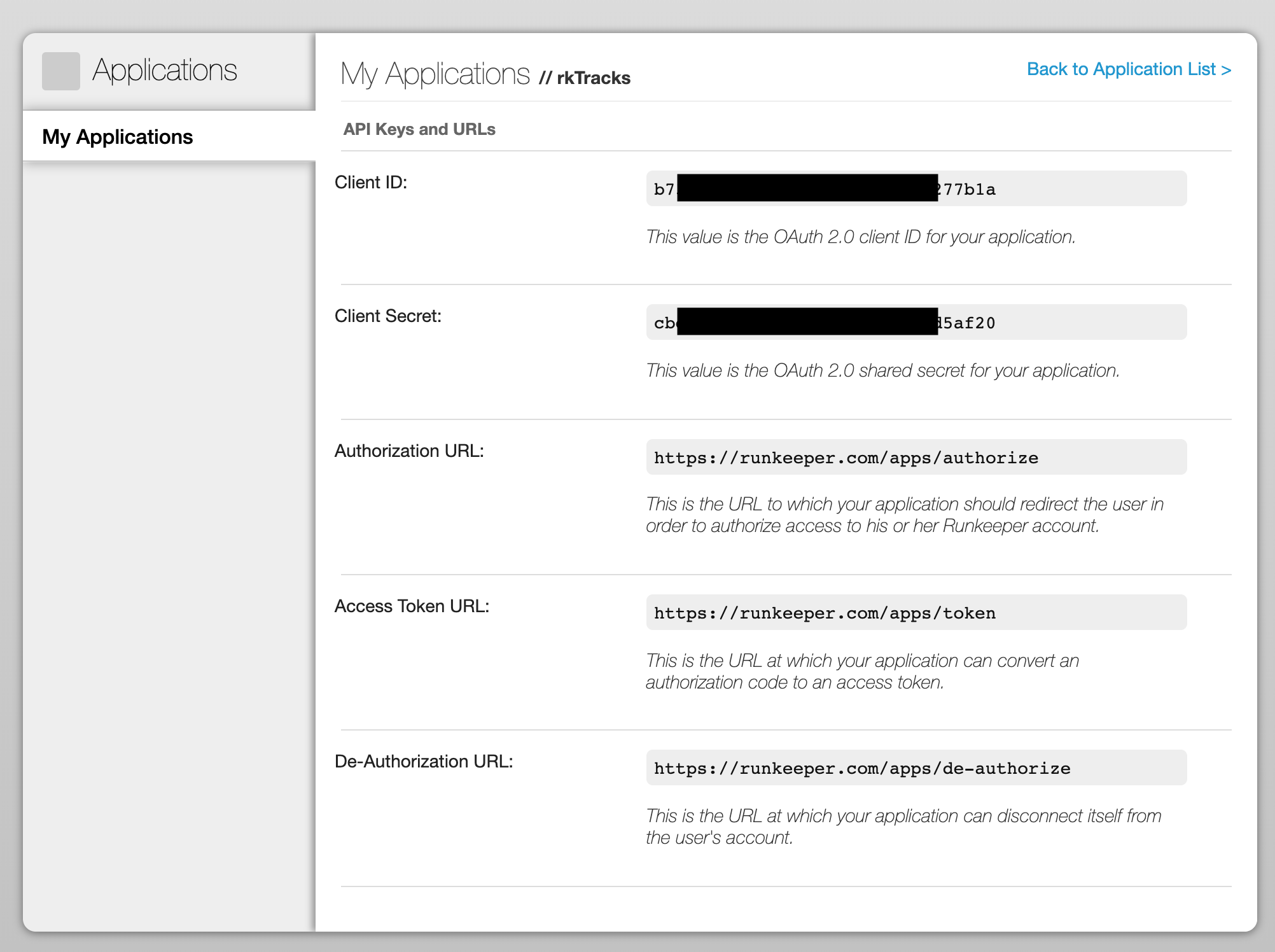
Once we’ve signed up and got access to the API, we are provided with a client_id and a client_secret. These are the OAuth keys that identify our application to Runkeeper:
To access user data from Runkeeper we need to follow a typical OAuth flow. We open a URL, sending Runkeeper our client_id and client_secret. Runkeeper asks our user to login and give our application permission to access their data. They then send us back to our redirect address with a single use access_code. We can then make a request to Runkeeper and exchange this access_code for an access_token. This token will allow us to make requests to the Health Graph API and access the data of the user that authorised our application. If we were building a public-facing application we’d need to write a bit of server code and get it online somewhere to handle this flow, but for our purposes here we only need to authorise ourselves, so we won’t bother and we’ll do it all manually.
Putting together the first request URL is quite straightforward:
from _credentials import client_id, client_secret, access_token
DATA_DIR = os.path.join(os.getcwd(),"data")
defget_auth_url(): # create an authorisation url to copy paste into a browser window # so we can get an access token to store in _credentials.py
Once we have the auth_url we can open it in a web browser. This will open the Runkeeper website and ask us to give permission to our application to access the necessary data:
If we authorise the application, it will send us back to our redirect URL. A proper server would listen for these requests coming in, capture the code provided in the address bar and carry on with the authentication flow. Again, we’re just doing it manually, so we’ll just copy and paste that code out of the address bar so we can use it in the next step of the process:
r = requests.get(base_url + endpoint, params=params, headers=headers) if r.status_code !=200: returnNone return r.json()
The above function will make a request to the given endpoint (and assuming it succeeds) will return the data back to the calling code. If we want to get the list of all activities for the user, we can use this function like so:
defget_fitness_activities(): # store activity URIs separately withopen("activities.json","w")as activities_output_file:
if activity_data.get("items"): activities.extend(activity_data["items"]) print(call_count,len(activity_data["items"]),len(activities))
while activity_data.get("next")and call_count < num_calls: activity_data = get_data(activity_data["next"]) call_count +=1
if activity_data.get("items"): activities.extend(activity_data["items"]) print(call_count,len(activity_data["items"]),len(activities))
json.dump(activities, activities_output_file)
The list of activities in the Health Graph is paginated, so we need to call the endpoint repeatedly, fetching each page of activities.
Once we have downloaded the full list of activities, we can then download the full details of each activity. The API is rate-limited to 100 calls every 15 minutes per user, so we’ll put the code to sleep for 9 seconds between calls to ensure we don’t go over the rate limit:
defdownload_activities(activity_list):
for activity_uri in activity_list: id_str = activity_uri.replace("/fitnessActivities/","") filename = os.path.join(DATA_DIR,"%s.json"% id_str) ifnot os.path.exists(filename): activity_data = get_data(activity_uri) time.sleep(9) if activity_data isnotNone: withopen(filename,"w")as output_file: json.dump(activity_data, output_file)
And that’s it. Run the code, give it enough time, and you’ll end up with all your activity data downloaded from Runkeeper. Easy.
The full code for the script is below, or in this gist here.